The arrival of any new medium has always been a catalyst for artistic change, and generative AI is the latest tool to reshape creative boundaries. For experimental creators, new tools represent an opportunity to experiment and a chance to evolve their practice. The three profiles that follow feature artists who’ve built careers on their craft: using film stock, physical materials, and the irreplaceable presence of human performers. They’ve also built careers on restlessness and experimentation. When it comes to the latest developments in generative AI, they approached it the way artists have always approached new tools—with equal parts curiosity and skepticism, seeing what breaks and what works.
Their recent projects show what happens when traditional artistic vision meets technology that’s still being figured out. The process isn’t always clean, and the results don’t follow predictable paths, but that’s precisely why these artists remain worth watching: They’re more interested in what’s possible than in what’s proper.
Darren Aronofsky
About the artist: Darren Aronofsky has spent his career pushing filmmaking technology to its limits, from the disorienting handheld camera shots in Pi to the visceral body horror of The Wrestler. His new venture, a creative technology company called Primordial Soup, continues to innovate moviemaking by partnering directly with the people building the technology. The studio partnered with Google DeepMind to explore what becomes possible when filmmakers work alongside AI researchers during development.
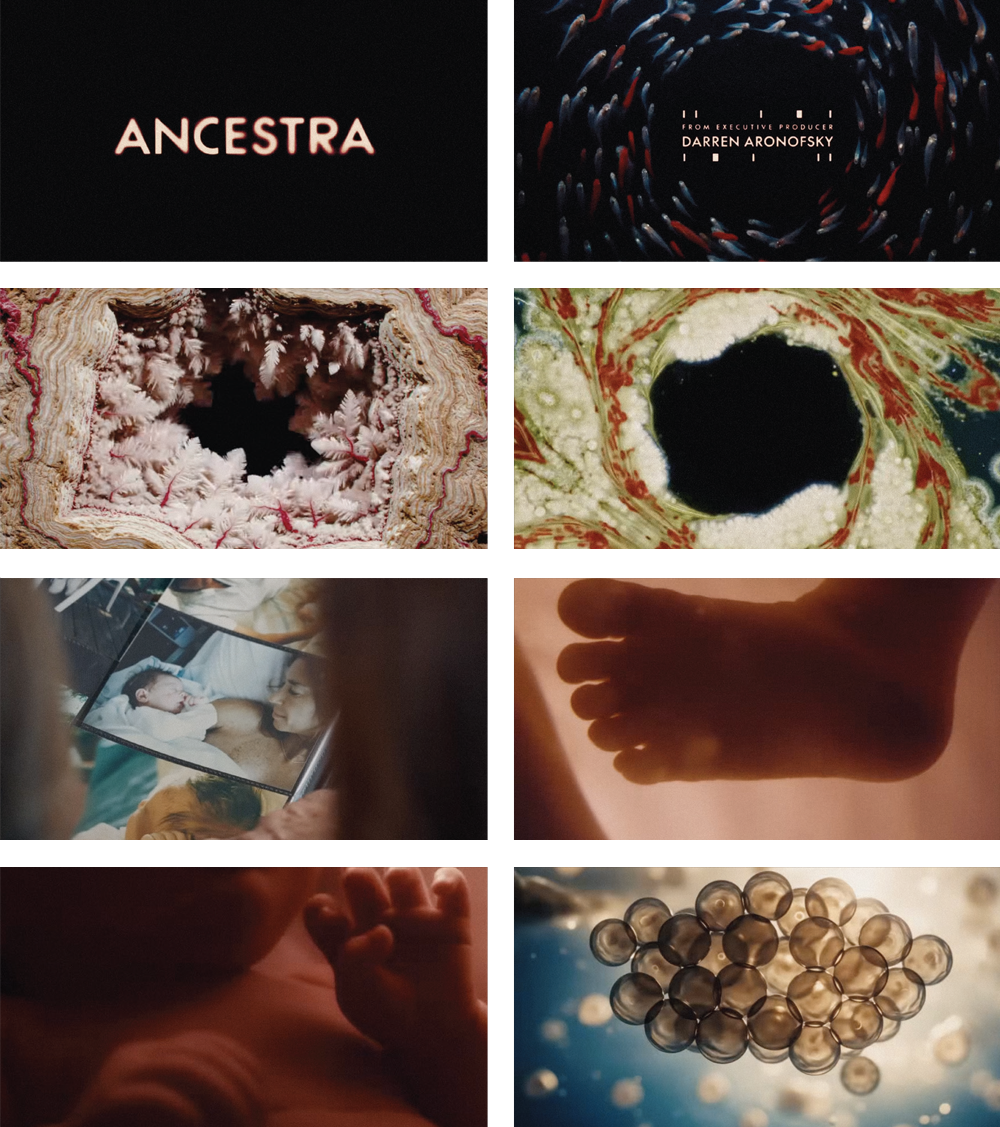
About the work: Ancestra, directed by Eliza McNitt, is the first project from this partnership. The short film tells the story of a mother and child at the moment of birth, drawing on McNitt’s experience of being born with a heart condition.
Traditional options for depicting an infant in film—like using a doll, a CGI baby that risks looking uncanny, or a real infant on set—all have drawbacks and are time-consuming for directors. Instead, the Primordial Soup team fed McNitt’s childhood photographs into a Google image-generation model and created an AI infant that looked like her. The team filmed the actress, Audrey Corsa, holding empty air, then added AI-generated footage of the baby into her arms. For a shot that travels through the interior of a human body, McNitt mapped the exact camera path she wanted on a 3D anatomical model, then used Veo, Google’s state-of-the-art video-generation model, to transform that technical 3D model into footage with cinematic texture and lighting. The process involved visual-effects artists, animators, and engineers working in extended collaboration, expanding the range of what a small team could practically achieve.
Google’s Veo is a state-of-the-art AI video-generation model that creates high-quality, cinematic videos from text or image prompts. Simply describe what you have in mind or upload a photo, and watch your ideas come to life, with audio.

Connie He
About the artist: Connie He is an animation director and story artist. Her professional background includes work on animated feature films such as Inside Out 2 and Dream Productions at Pixar from 2021 to 2024, while her first short film, Watermelon: A Cautionary Tale, is a viral success, with more than 200 million views on YouTube.
Her love for art was fostered by her father, a professional painter, who taught her from a young age to use it as a vehicle to express ideas that we have no words for. “I remember the first time he showed me an abstract expressionist painting,” she says. “I was blown away by how much emotion I could feel in the brushstrokes and the colors. I’ve been chasing the visceral feeling of those paintings my entire career in animation.”
However, painterly styles are notoriously difficult to achieve in a typical computer graphics workflow, especially ones with the thick, gritty brushstrokes that she aspires to. While this style is physically possible, a five-minute film would require 7,200 hand-painted frames (assuming the standard 24 frames per second), making it prohibitively time-consuming and unrealistic for production. Instead, He saw the potential of AI to help bring this monumental task to life, leading her to adopt this technology early.
By using Veo, Imagen, and Music AI Sandbox, she and her team have been creating an animated short in an innovative collaboration between artists and technology reminiscent of the early days of Pixar, showing just how powerful these tools can be when combined with creativity and artistic vision. “The look our 45-person film crew has achieved has never before been seen on film and would absolutely not have been possible without AI assistance.”
In addition to working with Google’s generative media models, such as Veo and Imagen, He and Grammy-winning composer Yung Spielburg have used Music AI Sandbox, a set of experimental tools that help artists generate fresh instrumental ideas, craft vocal arrangements, or simply break through a creative block.

Wade and Leta
About the artist: Wade Jeffree and Leta Sobierajski are a Brooklyn-based design duo who create large-scale interactive installations. Their work emphasizes accessibility and participation—they want people of all ages and backgrounds to engage physically with what they make. When Google approached them about using generative AI to develop a public sculpture, their first reaction was skepticism. “Since most people are creatures of comfort, sometimes you’re scared to try something new,” they explained. But they’ve also built their practice on experimentation. “We’d rather embrace new technologies than push them away as a way to help us create new work and for us to not remain stagnant in what our processes are.”
About the work: Reflection Point, unveiled at Rockefeller Center’s plaza, is a mirrored maze with bold geometric shapes designed for visitors to walk through and explore. The sculpture grew out of Wade and Leta’s collaboration with Google Labs, which began in May 2024. They used Google’s image-generation tools throughout the design process—not as a replacement for their usual workflow of sketching and model-making, but as a way to generate unexpected visual directions quickly.
The generative AI tools helped Wade and Leta create “fantastical and extremely diverse ideas”—enough visual possibilities that it forced them to take creative turns they wouldn’t have otherwise considered. By uploading reference images of subjects and scenes they found compelling, the generated variations pushed beyond what they might have conceived on their own. “That’s why we’re engaged with the technology: because it could allow us to take a right turn where we would typically go left.” They’d sketch by hand, build physical models, then return to the AI tools to test new approaches. The installation was on view through July 2025.
Artists can create captivating images in seconds with the Gemini app. From work to play and anything in between, the Gemini app can help you generate and refine images and bring your imagination to life.



